Home
People
Events
Research
Publications
Contact
News
1
Wisdom From File Systems: Fast and Reliable Update for Graph-based Vector Search via Soft Insert
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Yanqi Pan
,
Jiahao Chen
,
Hao Huang
,
Wen Xia
,
Shiyi Li
,
Chentao Wu
,
Xiangyu Zou
,
Jianzong Wang
Cite
Revisiting Aliasing in GAN Vocoders: Improving Intermediate Feature Representations
TBD
Jianzong Wang
,
Zitong Li
,
Xiaoyang Qu
,
Kang Wei
,
Xulong Zhang
Cite
DIVA: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement
Unified Multimodal models (UMMs) built on a single architecture have shown impressive performance in both understanding and generation. …
Renjie Lu
,
Xulong Zhang
,
Xiaoyang Qu
,
Shangfei Wang
,
Jianzong Wang
Cite
Code
arXiv
From Inheritance to Saturation: Disentangling the Evolution of Visual Redundancy for Architecture-Aware MLLM Inference Acceleration
High-resolution Multimodal Large Language Models (MLLMs) face prohibitive computational costs during inference due to the explosion of …
Jiaqi Shi
,
Xulong Zhang
,
Yuechan Li
,
Xiaoyang Qu
,
Jianzong Wang
Cite
ACL
VLA-InfoEntropy: A Training-Free Vision-Attention Information Entropy Approach for Vision-Language-Action Models Inference Acceleration and Success
Chuhang Liu
,
Yayun He
,
Zuheng Kang
,
Xiaoyang Qu
,
Jianzong Wang
Cite
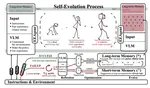
Evolvable Embodied Agent for Robotic Manipulation via Long Short-Term Reflection and Optimization
Achieving general-purpose robotics requires empowering robots to adapt and evolve based on their environment and feedback. Traditional …
Jianzong Wang
,
Botao Zhao
,
Yayun He
,
Junqing Peng
,
Xulong Zhang
Cite
arXiv
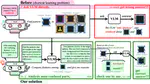
Confusion-Aware In-Context-Learning for Vision-Language Models in Robotic Manipulation
Vision-language models (VLMs) have significantly improved the generalization capabilities of robotic manipulation. However, VLM-based …
Yayun He
,
Zuheng Kang
,
Botao Zhao
,
Zhouyin Wu
,
Junqing Peng
,
Jianzong Wang
Cite
arXiv
Attention-weighted Centered Kernel Alignment for Knowledge Distillation in Large Audio-Language Models Applied to Speech Emotion Recognition
The emergence of Large Audio-Language Models (LALMs) has advanced Speech Emotion Recognition (SER), but their size limits deployment in …
Qingran Yang
,
Botao Zhao
,
Zuheng Kang
,
Xue Li
,
Yayun He
,
Chuhang Liu
,
Xulong Zhang
,
Xiaoyang Qu
,
Junqing Peng
,
Jianzong Wang
Cite
arXiv
IEEE
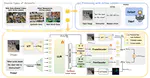
CARE: Multi-Task Pretraining for Latent Continuous Action Representation in Robot Control
Recent advances in Vision-Language-Action (VLA) models have shown promise for robot control, but their dependence on action supervision …
Jiaqi Shi
,
Xulong Zhang
,
Xiaoyang Qu
,
Jianzong Wang
Cite
arXiv
IEEE
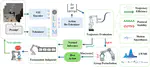
From Knowing to Doing Precisely: A General Self-Correction and Termination Framework for VLA Models
While vision-language-action (VLA) models for embodied agents integrate perception, reasoning, and control, they remain constrained by …
Wentao Zhang
,
Aolan Sun
,
Wentao Mo
,
Xiaoyang Qu
,
Yuxin Zheng
,
Jianzong Wang
Cite
arXiv
IEEE
»
Cite
×