Home
People
Events
Research
Publications
Contact
News
1
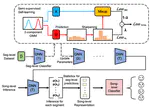
Investigation of Music Emotion Recognition Based on Segmented Semi-Supervised Learning
The production and annotation of music datasets requires very specialized background knowledge, which is difficult for most people to …
Yifu Sun
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Kaiyu Hu
,
Jing Xiao
PDF
Cite
ISCA
Prompt Guided Copy Mechanism for Conversational Question Answering
Conversational Question Answering (CQA) is a challenging task that aims to generate natural answers for conversational flow questions. …
Yong Zhang
,
Zhitao Li
,
Jianzong Wang
,
Yiming Gao
,
Ning Cheng
,
Fengying Yu
,
Jing Xiao
PDF
Cite
arXiv
ISCA
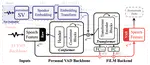
SVVAD: Personal Voice Activity Detection for Speaker Verification
Voice activity detection (VAD) improves the performance of speaker verification (SV) by preserving speech segments and attenuating the …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
PDF
Cite
Slides
arXiv
ISCA
SAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features …
Jianzong Wang
,
Xulong Zhang
,
Haobin Tang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
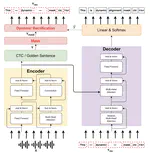
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of …
Xulong Zhang
,
Haobin Tang
,
Jianzong Wang
,
Ning Cheng
,
Jian Luo
,
Jing Xiao
Cite
arXiv
IEEE
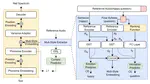
Improving EEG-based Emotion Recognition by Fusing Time-frequency And Spatial Representations
Using deep learning methods to classify EEG signals can accurately identify people’s emotions. However, existing studies have …
Kexin Zhu
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
Poster
arXiv
IEEE
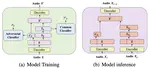
Improving Music Genre Classification from Multi-modal Properties of Music and Genre Correlations Perspective
Music genre classification has been widely studied in past few years for its various applications in music information retrieval. …
Ganghui Ru
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
Poster
arXiv
IEEE
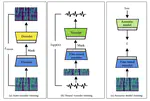
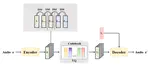
Learning Speech Representations with Flexible Hidden Feature Dimensions
Non-parallel many-to-many voice conversion is a kind of style transfer task in speech. Recently, AutoVC has been applied in this field …
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
IEEE
QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
VQ-CL: Learning Disentangled Speech Representations with Contrastive Learning and Vector Quantization
Voice Conversion(VC) refers to converting the voice char- acteristics of audio to another one as it is said by other people. Recently, …
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
IEEE
«
»
Cite
×