Home
People
Events
Research
Publications
Contact
News
1
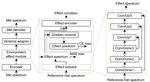
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
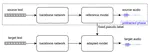
Adapitch: Adaption Multi-Speaker Text-to-Speech Conditioned on Pitch Disentangling with Untranscribed Data
In this paper, we proposed Adapitch, a multi-speaker TTS method that makes adaptation of the supervised module with untranscribed data. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Improving Imbalanced Text Classification with Dynamic Curriculum Learning
Recent advances in pre-trained language models have improved the performance for text classification tasks. However, little attention …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
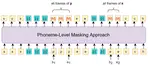
Improving Speech Representation Learning via Speech-level and Phoneme-level Masking Approach
Recovering the masked speech frames is widely applied in speech representation learning. However, most of these models use random …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Kexin Zhu
,
Jing Xiao
Cite
arXiv
IEEE
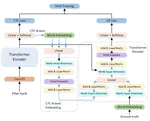
Linguistic-Enhanced Transformer with CTC Embedding for Speech Recognition
The recent emergence of joint CTC-Attention model shows significant improvement in automatic speech recognition (ASR). The improvement …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Mengyuan Zhao
,
Zhiyong Zhang
,
Jing Xiao
Cite
arXiv
IEEE
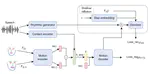
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
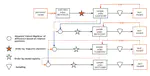
Semi-Supervised Learning Based on Reference Model for Low-resource TTS
Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Shallow Diffusion Motion Model for Talking Face Generation from Speech
Talking face generation is synthesizing a lip synchronized talking face video by inputting an arbitrary face image and audio clips. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Edward Xiao
,
Jing Xiao
PDF
Cite
Springer
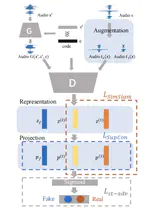
Boosting Star-GANs for Voice Conversion with Contrastive Discriminator
Nonparallel multi-domain voice conversion methods such as the StarGAN-VCs have been widely applied in many scenarios. However, the …
Shijing Si
,
Jianzong Wang
,
Xulong Zhang
,
Xiaoyang Qu
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous …
Aolan Sun
,
Xulong Zhang
,
Tiandong Ling
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
«
»
Cite
×