Home
People
Events
Research
Publications
Contact
News
1
PointActionCLIP: Preventing Transfer Degradation in Point Cloud Action Recognition with a Triple-Path CLIP
Directly applying CLIP to point cloud action recognition can cause severe accuracy collapse. In this paper, we propose PointActionCLIP, …
Wei Tao
,
Shenglin He
,
Xiaoyang Qu
,
Jiguang Wan
,
Jianzong Wang
PDF
Cite
IEEE
VisTa: Visual-contextual and Text-augmented Zero-shot Object-level OOD Detection
As object detectors are increasingly deployed as black-box cloud services or pre-trained models with restricted access to the original …
Bin Zhang
,
Xiaoyang Qu
,
Guokuan Li
,
Jiguang Wan
,
Jianzong Wang
PDF
Cite
arXiv
IEEE
ACCon: Angle-Compensated Contrastive Regularizer for Deep Regression
In deep regression, capturing the relationship among continuous labels in feature space is a fundamental challenge that has attracted …
Botao Zhao
,
Xiaoyang Qu
,
Zuheng Kang
,
Junqing Peng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
AAAI
RUNA: Object-level Out-of-Distribution Detection via Regional Uncertainty Alignment of Multimodal Representations
Enabling object detectors to recognize out-of-distribution (OOD) objects is vital for building reliable systems. A primary obstacle …
Bin Zhang
,
Jinggang Chen
,
Xiaoyang Qu
,
Guokuan Li
,
Kai Lu
,
Jiguang Wan
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
AAAI
Cocktail:Chunk-AdaptiveMixed-Precision Ouanization for Long-Context LLM inference
Recently, large language models (LLMs) have been able to handle longer and longer contexts. However, a context that is too long may …
Wei Tao
,
Bin Zhang
,
Xiaoyang Qu
,
Jiguang Wan
,
Jianzong Wang
Cite
arXiv
IEEE
Incremental Label Distribution Learning With Scalable Graph Convolutional Networks
Label Distribution Learning (LDL) is an effective approach for handling label ambiguity, as it can analyze all labels at once and …
Ziqi Jia
,
Xiaoyang Qu
,
Chenghao Liu
,
Jianzong Wang
Cite
arXiv
IEEE
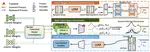
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional …
Pengcheng Li
,
Xulong Zhang
,
Jing Xiao
,
Jianzong Wang
Cite
Code
arXiv
ACL
DEMO
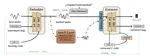
FormerReckoning: Physics Inspired Transformer for Accurate Inertial Navigation
Although modern localization methods have achieved remarkable accuracy with various sensors, there are still some circumstances where …
Jiaqi Li
,
Chenyu Zhao
,
Yuzhu Mao
,
Xinlei Chen
,
Wenbo Ding
,
Xiaoyang Qu
,
Jianzong Wang
PDF
Cite
ACM
Beyond Aggregation: Efficient Federated Model Consolidation with Heterogeneity-Adaptive Weights Diffusion
As the Internet of Things (IoT) evolves, the need for enhanced data-sharing to improve edge device performance has led to the adoption …
Jiaqi Li
,
Xiaoyang Qu
,
Wenbo Ding
,
Zihao Zhao
,
Jianzong Wang
Cite
ACM
数字说话人脸生成技术综述
Bingyuan Zhang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Last updated on Sep 29, 2025
Cite
«
»
Cite
×