Home
People
Events
Research
Publications
Contact
News
1
Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning
Instruction tuning is critical to improve LLMs but usually suffers from low-quality and redundant data. Data filtering for instruction …
Ming Li
,
Yong Zhang
,
Shwai He
,
Zhitao Li
,
Hongyu Zhao
,
Jianzong Wang
,
Ning Cheng
,
Tianyi Zhou
Cite
Code
arXiv
ACL
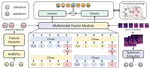
Enhancing Emotion Prediction and Recognition in Conversation through Fine-Grained Emotional Cue Analysis and Cross-Modal Fusion
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual …
Haoxiang Shi
,
Xulong Zhang
,
Ning Cheng
,
Yong Zhang
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Springer
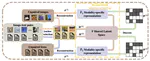
RREH: Reconstruction Relations Embedded Hashing for Semi-Paired Cross-Modal Retrieval
Known for efficient computation and easy storage, hashing has been extensively explored in cross-modal retrieval. The majority of …
Jianzong Wang
,
Haoxiang Shi
,
Kaiyi Luo
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
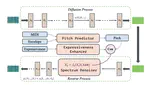
RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing …
Haoxiang Shi
,
Jianzong Wang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
Cite
arXiv
Springer
Retrieval-Augmented Audio Deepfake Detection
With recent advances in speech synthesis including text-to-speech (TTS) and voice conversion (VC) systems enabling the generation of …
Zuheng Kang
,
Yayun He
,
Botao Zhao
,
Xiaoyang Qu
,
Junqing Peng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
ACM
CONTUNER: Singing Voice Beautifying with Pitch and Expressiveness Condition
Singing voice beautifying is a novel task that has application value in people’s daily life, aiming to correct the pitch of the …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
DEMO
IEEE
EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot …
Ziqi Liang
,
Jianzong Wang
,
Xulong Zhang
,
Yong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
DEMO
IEEE
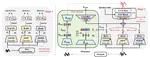
Efficient Multi-Model Fusion with Adversarial Complementary Representation Learning
Single-model systems often suffer from deficiencies in tasks such as speaker verification (SV) and image classification, relying …
Zuheng Kang
,
Yayun He
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
EfficientASR: Speech Recognition Network Compression via Attention Redundancy and Chunk-Level FFN Optimization
In recent years, Transformer networks have shown remarkable performance in speech recognition tasks. However, their deployment poses …
Jianzong Wang
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Enhancing Anomalous Sound Detection with Multi-Level Memory Bank
Abnormal sound detection (ASD) is crucial for the timely detection of machine faults in industrial scenarios and has emerged as a …
Baoping Deng
,
Jinggang Chen
,
Zhenhou Hong
,
Xiaoyang Qu
,
Guokuan Li
,
Jiguang Wan
,
Changsheng Xie
,
Jianzong Wang
Cite
IEEE
«
»
Cite
×