Home
People
Events
Research
Publications
Contact
News
1
MAIN-VC: Lightweight Speech Representation Disentanglement for One-Shot Voice Conversion
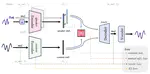
One-shot voice conversion aims to change the timbre of any source speech to match that of the unseen target speaker with only one …
Pengcheng Li
,
Jianzong Wang
,
Xulong Zhang
,
Yong Zhang
,
Jing Xiao
,
Ning Cheng
Cite
arXiv
DEMO
IEEE
PRENet: A Plane-Fit Redundancy Encoding Point Cloud Sequence Network for Real-Time 3D Action Recognition
Recognizing human actions from point cloud sequence has attracted tremendous attention from both academia and industry due to its wide …
Shenglin He
,
Xiaoyang Qu
,
Jiguang Wan
,
Guokuan Li
,
Changsheng Xie
,
Jianzong Wang
Cite
arXiv
IEEE
QLSC: A Query Latent Semantic Calibrator for Robust Extractive Question Answering
Extractive Question Answering (EQA) in Machine Reading Comprehension (MRC) often faces the challenge of dealing with semantically …
Sheng Ouyang
,
Jianzong Wang
,
Yong Zhang
,
Zhitao Li
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
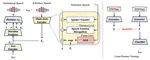
Task-Agnostic Decision Transformer for Multi-Type Agent Control with Federated Split Training
With the rapid advancements in artificial intelligence, the development of knowledgeable and personalized agents has become …
Zhiyuan Wang
,
Bokui Chen
,
Xiaoyang Qu
,
Zhenhou Hong
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
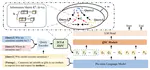
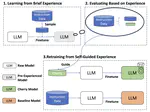
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
In the realm of Large Language Models, the balance between instruction data quality and quantity has become a focal point. Recognizing …
Ming Li
,
Yong Zhang
,
Zhitao Li
,
Jiuhai Chen
,
Lichang Chen
,
Ning Cheng
,
Jianzong Wang
,
Tianyi Zhou
,
Jing Xiao
Cite
Code
arXiv
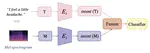
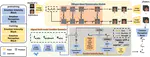
Medical Speech Symptoms Classification via Disentangled Representation
Intent is defined for understanding spoken language in existing works. Both textual features and acoustic features involved in medical …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
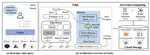
Gecko: Resource-Efficient and Accurate Queries in Real-Time Video Streams at the Edge
Surveillance cameras are ubiquitous nowadays and users’ increasing needs for accessing real-world information (e.g., finding abandoned …
Liang Wang
,
Xiaoyang Qu
,
Jianzong Wang
,
Guokuan Li
,
Jiguang Wan
,
Nan Zhang
,
Song Guo
,
Jing Xiao
PDF
Cite
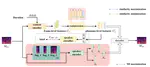
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating …
Bingyuan Zhang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Dataset
IEEE
ED-TTS: Multi-Scale Emotion Modeling Using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting …
Haobin Tang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations …
Yimin Deng
,
Huaizhen Tang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
«
»
Cite
×