Home
People
Events
Research
Publications
Contact
News
1
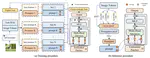
INCPrompt: Task-Aware Incremental Prompting for Rehearsal-Free Class-incremental Learning
This paper introduces INCPrompt, an innovative continual learning solution that effectively addresses catastrophic forgetting. …
Zhiyuan Wang
,
Xiaoyang Qu
,
Jing Xiao
,
Bokui Chen
,
Jianzong Wang
Cite
arXiv
IEEE
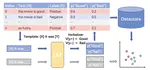
Leveraging Biases in Large Language Models: bias-kNN for Effective Few-Shot Learning
Large Language Models (LLMs) have shown significant promise in various applications, including zero-shot and few-shot learning. …
Yong Zhang
,
Hanzhang Li
,
Zhitao Li
,
Ning Cheng
,
Ming Li
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
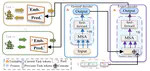
P2DT: Mitigating Forgetting in Task-Incremental Learning with Progressive Prompt Decision Transformer
Catastrophic forgetting poses a substantial challenge for managing intelligent agents controlled by a large model, causing performance …
Zhiyuan Wang
,
Xiaoyang Qu
,
Jing Xiao
,
Bokui Chen
,
Jianzong Wang
Cite
arXiv
IEEE
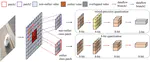
Value-Driven Mixed-Precision Quantization for Patch-Based Inference on Microcontrollers
Deploying neural networks on microcontroller units (MCUs) presents substantial challenges due to their constrained computation and …
Wei Tao
,
Shenglin He
,
Kai Lu
,
Xiaoyang Qu
,
Guokuan Li
,
Jiguang Wan
,
Jianzong Wang
,
Jing Xiao
Cite
arXiv
IEEE
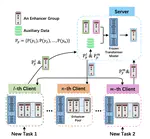
FedET: A Communication-Efficient Federated Class-Incremental Learning Framework Based on Enhanced Transformer
Federated Learning (FL) has been widely con- cerned for it enables decentralized learning while ensuring data privacy. However, most …
Chenghao Liu
,
Xiaoyang Qu
,
Jianzong Wang
,
Jing Xiao
PDF
Cite
arXiv
IJCAI
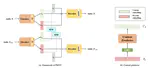
GAIA: Delving into Gradient-based Attribution Abnormality for Out-of-distribution Detection
Detecting out-of-distribution (OOD) examples is crucial to guarantee the reliability and safety of deep neural networks in real-world …
Jinggang Chen
,
Junjie Li
,
Xiaoyang Qu
,
Jianzong Wang
,
Jiguang Wan
,
Jing Xiao
PDF
Cite
Poster
Slides
On the Calibration and Uncertainty with Pólya-Gamma Augmentation for Dialog Retrieval Models
Deep neural retrieval models have amply demonstrated their power but estimating the reliability of their predictions remains …
Tong Ye
,
Shijing Si
,
Jianzong Wang
,
Ning Cheng
,
Zhitao Li
,
Jing Xiao
PDF
Cite
arXiv
AAAI
PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Voice conversion as the style transfer task applied to speech, refers to converting one person’s speech into a new speech that …
Yimin Deng
,
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
DEMO
ACM
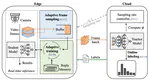
Shoggoth: Towards Efficient Edge-Cloud Collaborative Real-Time Video Inference via Adaptive Online Learning
This paper proposes Shoggoth, an efficient edge-cloud collaborative architecture, for boosting inference performance on real-time video …
Liang Wang
,
Kai Lu
,
Nan Zhang
,
Xiaoyang Qu
,
Jianzong Wang
,
Jiguang Wan
,
Guokuan Li
,
Jing Xiao
Cite
arXiv
CLN-VC: Text-Free Voice Conversion Based on Fine-Grained Style Control and Contrastive Learning with Negative Samples Augmentation
Better disentanglement of speech representation is essential to improve the quality of voice conversion. Recently contrastive learning …
Yimin Deng
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
«
»
Cite
×