Home
People
Events
Research
Publications
Contact
News
1
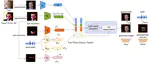
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
This paper proposes a talking face generation method named “CP-EB” that takes an audio signal as input and a person image as reference, …
Jianzong Wang
,
Yimin Deng
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
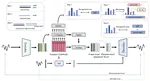
DQR-TTS: Semi-supervised Text-to-speech Synthesis with Dynamic Quantized Representation
Most existing neural-based text-to-speech methods rely on extensive datasets and face challenges under low-resource condition. In this …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
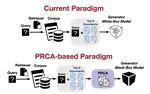
PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter
The Retrieval Question Answering (ReQA) task employs the retrieval-augmented framework, composed of a retriever and generator. The …
Haoyan Yang
,
Zhitao Li
,
Yong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Ming Li
,
Jing Xiao
PDF
Cite
arXiv
ACL
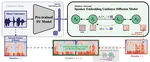
VoiceExtender: Short-utterance Text-independent Speaker Verification with Guided Diffusion Model
Speaker Verification (SV) performance gets worse as utterances get shorter. To this end, we propose a new architecture called …
Yayun He
,
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
AOSR-Net: All-in-One Sandstorm Removal Network
Most existing sandstorm image enhancement methods are based on traditional theory and prior knowledge, which often limit their …
Yazhong Si
,
Xulong Zhang
,
Fan Yang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Contrastive Latent Space Reconstruction Learning for Audio-Text Retrieval
Cross-modal retrieval (CMR) has been widely applied in a wide range of applications, such as multimedia search engines, recommendation …
Kaiyi Luo
,
Xulong Zhang
,
Jianzong Wang
,
Huaxiong Li
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic …
Jianzong Wang
,
Xulong Zhang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
DEMO
A Hierarchy-based Analysis Approach for Blended Learning: A Case Study with Chinese Students
Blended learning is generally defined as the combination of traditional face-to-face learning and online learning. This learning mode …
Yu Ye
,
Gongjin Zhang
,
Hongbiao Si
,
Liang Xu
,
Shenghua Hu
,
Yong Li
,
Xulong Zhang
,
Kaiyu Hu
,
Fangzhou Ye
Cite
arXiv
Springer
An Empirical Study of Attention Networks for Semantic Segmentation
Semantic segmentation is a vital problem in computer vision. Recently, a common solution to semantic segmentation is the end-to-end …
Hao Guo
,
Hongbiao Si
,
Guilin Jiang
,
Wei Zhang
,
Zhiyan Liu
,
Xuanyi Zhu
,
Xulong Zhang
,
Yang Liu
Cite
arXiv
Springer
Research on the Impact of Executive Shareholding on New Investment in Enterprises Based on Multivariable Linear Regression Model
Based on principal-agent theory and optimal contract theory, companies use the method of increasing executives’ shareholding to …
Shanyi Zhou
,
Ning Yan
,
Zhijun Li
,
Mo Geng
,
Xulong Zhang
,
Hongbiao Si
,
Lihua Tang
,
Wenyuan Sun
,
Longda Zhang
,
Yi Cao
Cite
arXiv
Springer
«
»
Cite
×