Home
People
Events
Research
Publications
Contact
News
1
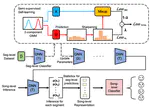
Stock Volatility Prediction Based on Transformer Model Using Mixed-Frequency Data
With the increasing volume of high-frequency data in the information age, both challenges and opportunities arise in the prediction of …
Wenting Liu
,
Zhaozhong Gui
,
Guilin Jiang
,
Lihua Tang
,
Lichun Zhou
,
Wan Leng
,
Xulong Zhang
,
Yujiang Liu
Cite
arXiv
Springer
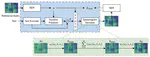
EdgeMA: Model Adaptation System for Real-Time Video Analytics on Edge Devices
Real-time video analytics on edge devices for changing scenes remains a difficult task. As edge devices are usually …
Liang Wang
,
Nan Zhang
,
Xiaoyang Qu
,
Jianzong Wang
,
Jiguang Wan
,
Guokuan Li
,
Kaiyu Hu
,
Guilin Jiang
,
Jing Xiao
Cite
arXiv
Machine Unlearning Methodology base on Stochastic Teacher Network
The rise of the phenomenon of the “right to be forgotten” has prompted research on machine unlearning, which grants data …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Yifu Sun
,
Chuanyao Zhang
,
Jing Xiao
Cite
arXiv
Springer
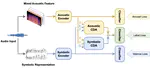
Symbolic and Acoustic: Multi-domain Music Emotion Modeling for Instrumental Music
Music Emotion Recognition involves the automatic identification of emotional elements within music tracks, and it has garnered …
Kexin Zhu
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
Voice Conversion with Denoising Diffusion Probabilistic GAN Models
Voice conversion is a method that allows for the transformation of speaking style while maintaining the integrity of linguistic …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
Boosting Chinese ASR Error Correction with Dynamic Error Scaling Mechanism
Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language’s unique …
Jiaxin Fan
,
Yong Zhang
,
Hanzhang Li
,
Jianzong Wang
,
Zhitao Li
,
Sheng Ouyang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
DEMO
Investigation of Music Emotion Recognition Based on Segmented Semi-Supervised Learning
The production and annotation of music datasets requires very specialized background knowledge, which is difficult for most people to …
Yifu Sun
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Kaiyu Hu
,
Jing Xiao
PDF
Cite
ISCA
Prompt Guided Copy Mechanism for Conversational Question Answering
Conversational Question Answering (CQA) is a challenging task that aims to generate natural answers for conversational flow questions. …
Yong Zhang
,
Zhitao Li
,
Jianzong Wang
,
Yiming Gao
,
Ning Cheng
,
Fengying Yu
,
Jing Xiao
PDF
Cite
arXiv
ISCA
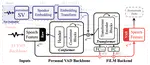
SVVAD: Personal Voice Activity Detection for Speaker Verification
Voice activity detection (VAD) improves the performance of speaker verification (SV) by preserving speech segments and attenuating the …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
PDF
Cite
Slides
arXiv
ISCA
«
»
Cite
×