 A system overview
A system overviewAbstract
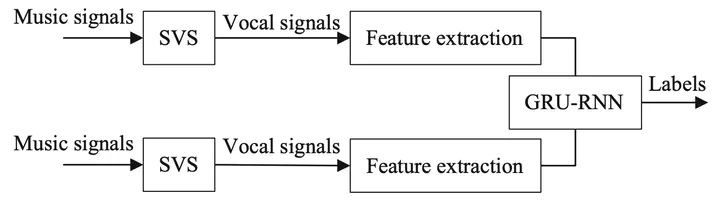
In this paper, we present a practical three-step approach for singing voice detection based on a gated recurrent unit (GRU) recurrent neural network (RNN) and the proposed method achieves comparable results to state-of-the-art method. We combine four classic features—namely Mel-frequency Cepstral Coefficients (MFCC), Mel-filter Bank, Linear Predictive Cepstral Coefficients (LPCC), and Chroma. Then, the mixed signal is first preprocessed by singing voice separation (SVS) with the Deep U-Net Convolutional Networks. Long short-term memory (LSTM) and GRU are both proposed to solve the gradient vanish problem in RNN. In our experiments, we set the block duration as 120 ms and 720 ms respectively, and we get comparable or better results than results from state-of-the-art methods, while results on Jamendo are not as good as those from RWC-Pop.