 GraphTTS model
GraphTTS modelAbstract
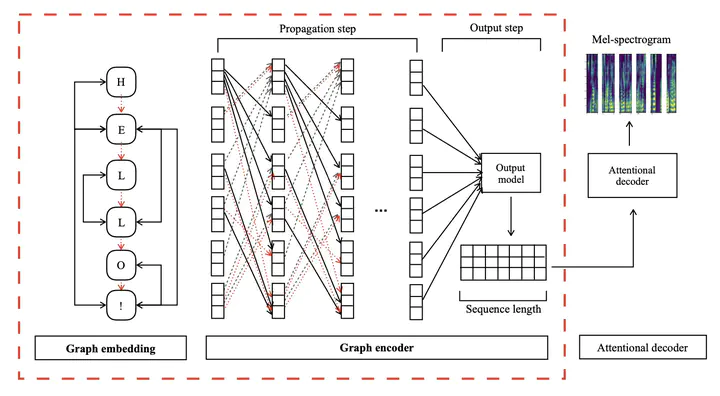
This paper leverages the graph-to-sequence method in neural text-to-speech (GraphTTS), which maps the graph embedding of the input sequence to spectrograms. The graphical inputs consist of node and edge representations constructed from input texts. The encoding of these graphical inputs incorporates syntax information by a GNN encoder module. Besides, applying the encoder of GraphTTS as a graph auxiliary encoder (GAE) can analyse prosody information from the semantic structure of texts. This can remove the manual selection of reference audios process and makes prosody modelling an end-to-end procedure. Experimental analysis shows that GraphTTS outperforms the state-of-the-art sequence-to-sequence models by 0.24 in Mean Opinion Score (MOS). GAE can adjust the pause, ventilation and tones of synthesised audios automatically. This experimental conclusion may give some inspiration to researchers working on improving speech synthesis prosody.