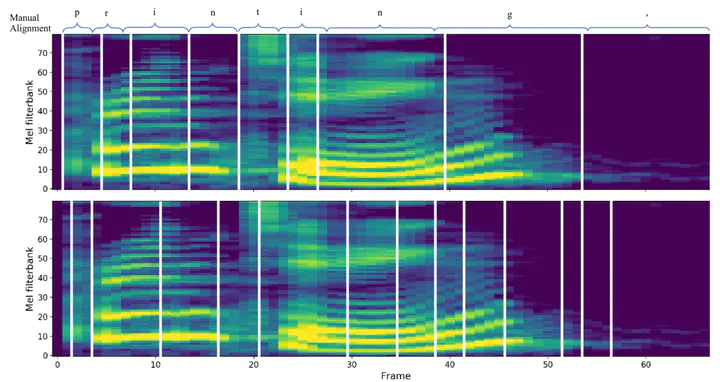
 Comparison of Alignments
Comparison of AlignmentsAbstract
Targeting at both high efficiency and performance, we propose AlignTTS to predict the mel-spectrum in parallel. AlignTTS is based on a Feed-Forward Transformer which generates mel-spectrum from a sequence of characters, and the duration of each character is determined by a duration predictor. Instead of adopting the attention mechanism in Transformer TTS to align text to mel-spectrum, the alignment loss is presented to consider all possible alignments in training by use of dynamic programming. Experiments on the LJSpeech dataset show that our model achieves not only state-of-the-art performance which outperforms Transformer TTS by 0.03 in mean option score (MOS), but also a high efficiency which is more than 50 times faster than real-time.
Type
Publication
In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.