 Model Training with Prosody Learning Mechanism and Prosody predictor
Model Training with Prosody Learning Mechanism and Prosody predictorAbstract
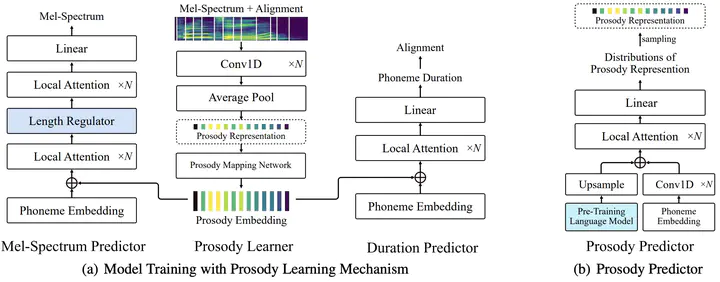
Recent neural speech synthesis systems have gradually focused on the control of prosody to improve the quality of synthesized speech, but they rarely consider the variability of prosody and the correlation between prosody and semantics together. In this paper, a prosody learning mechanism is proposed to model the prosody of speech based on TTS system, where the prosody information of speech is extracted from the mel-spectrum by a prosody learner and combined with the phoneme sequence to reconstruct the mel-spectrum. Meanwhile, the semantic features of text from the pre-trained language model is introduced to improve the prosody prediction results. In addition, a novel self-attention structure, named as local attention, is proposed to lift this restriction of input text length, where the relative position information of the sequence is modeled by the relative position matrices so that the position encodings is no longer needed. Experiments on English and Mandarin show that speech with more satisfactory prosody has obtained in our model. Especially in Mandarin synthesis, our proposed model outperforms baseline model with a MOS gap of 0.08, and the overall naturalness of the synthesized speech has been significantly improved.