Research on Singing Voice Detection Based on a Long-Term Recurrent Convolutional Network with Vocal Separation and Temporal Smoothing
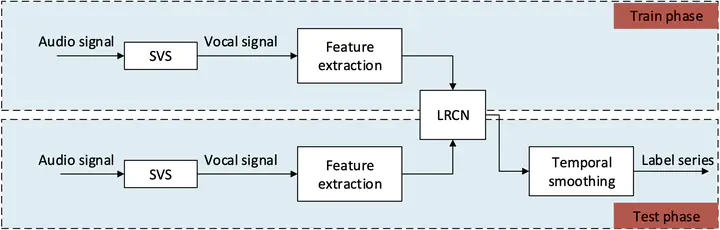 Overview of the proposed singing voice detection system
Overview of the proposed singing voice detection systemAbstract
Singing voice detection or vocal detection is a classification task that determines whether a given audio segment contains singing voices. This task plays a very important role in vocal-related music information retrieval tasks, such as singer identification. Although humans can easily distinguish between singing and nonsinging parts, it is still very difficult for machines to do so. Most existing methods focus on audio feature engineering with classifiers, which rely on the experience of the algorithm designer. In recent years, deep learning has been widely used in computer hearing. To extract essential features that reflect the audio content and characterize the vocal context in the time domain, this study adopted a long-term recurrent convolutional network (LRCN) to realize vocal detection. The convolutional layer in LRCN functions in feature extraction, and the long short-term memory (LSTM) layer can learn the time sequence relationship. The preprocessing of singing voices and accompaniment separation and the postprocessing of time-domain smoothing were combined to form a complete system. Experiments on five public datasets investigated the impacts of the different features for the fusion, frame size, and block size on LRCN temporal relationship learning, and the effects of preprocessing and postprocessing on performance, and the results confirm that the proposed singing voice detection algorithm reached the state-of-the-art level on public datasets.