 Active Learning Pipeline with Loss Prediction
Active Learning Pipeline with Loss PredictionAbstract
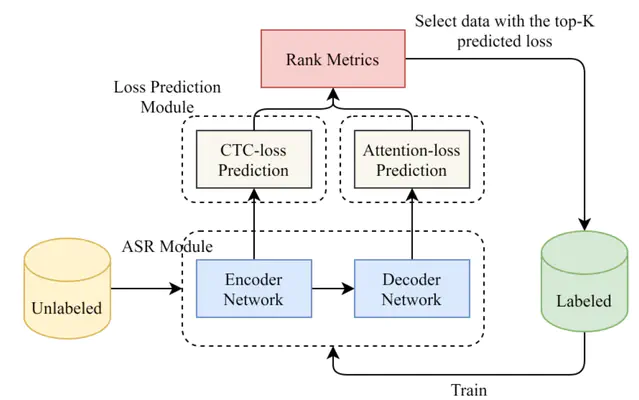
End-to-end speech recognition systems usually require huge amounts of labeling resource, while annotating the speech data is complicated and expensive. Active learning is the solution by selecting the most valuable samples for annotation. In this paper, we proposed to use a predicted loss that estimates the uncertainty of the sample. The CTC (Connectionist Temporal Classification) and attention loss are informative for speech recognition since they are computed based on all decoding paths and alignments. We defined an end-to-end active learning pipeline, training an ASR/LP (Automatic Speech Recognition/Loss Prediction) joint model. The proposed approach was validated on an English and a Chinese speech recognition task. The experiments show that our approach achieves competitive results, outperforming random selection, least confidence, and estimated loss method.