Multi-Quartznet: Multi-Resolution Convolution for Speech Recognition with Multi-Layer Feature Fusion
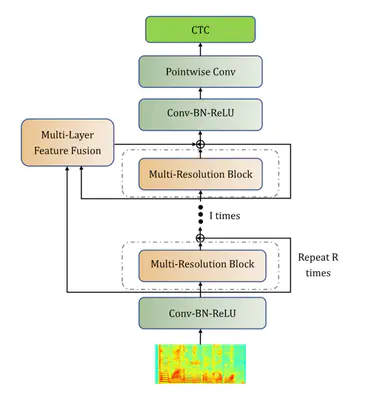 Multi-QuartzNet Model Architecture
Multi-QuartzNet Model ArchitectureAbstract
In this paper, we propose an end-to-end speech recognition network based on Nvidia’s previous QuartzNet [1] model. We try to promote the model performance, and design three components{:} (1) Multi-Resolution Convolution Module, re-places the original 1D time-channel separable convolution with multi-stream convolutions. Each stream has a unique dilated stride on convolutional operations. (2) Channel-Wise Attention Module, calculates the attention weight of each convolutional stream by spatial channel-wise pooling. (3) Multi-Layer Feature Fusion Module, reweights each convolutional block by global multi-layer feature maps. Our experiments demonstrate that Multi-QuartzNet model achieves CER 6.77% on AISHELL-1 data set, which outperforms original QuartzNet and is close to state-of-art result.