 Memory-Self-Attention Transducer
Memory-Self-Attention TransducerAbstract
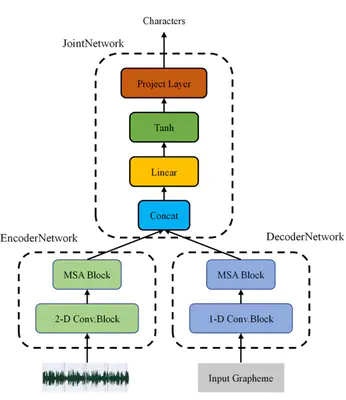
Self-attention models have been successfully applied in end-to-end speech recognition systems, which greatly improve the performance of recognition accuracy. However, such attention-based models cannot be used in online speech recognition, because these models usually have to utilize a whole acoustic sequences as inputs. A common method is restricting the field of attention sights by a fixed left and right window, which makes the computation costs manageable yet also introduces performance degradation. In this paper, we propose Memory-Self-Attention (MSA), which adds history information into the Restricted-Self-Attention unit. MSA only needs localtime features as inputs, and efficiently models long temporal contexts by attending memory states. Meanwhile, recurrent neural network transducer (RNN-T) has proved to be a great approach for online ASR tasks, because the alignments of RNN-T are local and monotonic. We propose a novel network structure, called Memory-Self-Attention (MSA) Transducer. Both encoder and decoder of the MSA Transducer contain the proposed MSA unit. The experiments demonstrate that our proposed models improve WER results than Restricted-Self-Attention models by 13.5% on WSJ and 7.1% on SWBD datasets relatively, and without much computation costs increase.