TGAVC: Improving Autoencoder Voice Conversion with Text-Guided and Adversarial Training
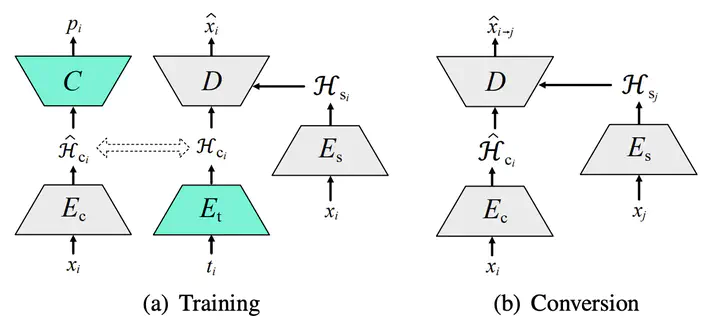 Framework of TGAVC
Framework of TGAVCAbstract
Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Recently, AutoVC, a conditional autoencoder based method, achieved excellent conversion results by disentangling the speaker identity and the speech content using information-constraining bottlenecks. However, due to the pure autoencoder training method, it is difficult to evaluate the separation effect of content and speaker identity. In this paper, a novel voice conversion framework, named Text Guided AutoVC(TGAVC), is proposed to more effectively separate content and timbre from speech, where an expected content embedding produced based on the text transcriptions is designed to guide the extraction of voice content. In addition, the adversarial training is applied to eliminate the speaker identity information in the estimated content embedding extracted from speech. Under the guidance of the expected content embedding and the adversarial training, the content encoder is trained to extract speaker-independent content embedding from speech. Experiments on AIShell-3 dataset show that the proposed model outperforms AutoVC in terms of naturalness and similarity of converted speech.