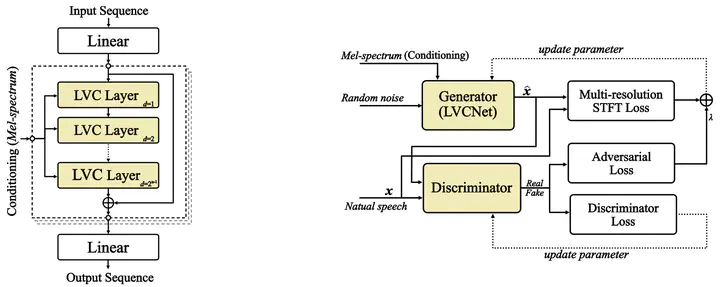
 The architecture of LVCNet
The architecture of LVCNetAbstract
In this paper, we propose a novel conditional convolution network, named location-variable convolution, to model the dependencies of the waveform sequence. Different from the use of unified convolution kernels in WaveNet to capture the dependencies of arbitrary waveform, the location-variable convolution uses convolution kernels with different coefficients to perform convolution operations on different waveform intervals, where the coefficients of kernels is predicted according to conditioning acoustic features, such as Mel-spectrograms. Based on location-variable convolutions, we design LVCNet for waveform generation, and apply it in Parallel WaveGAN to design more efficient vocoder. Experiments on the LJSpeech dataset show that our proposed model achieves a four-fold increase in synthesis speed compared to the original Parallel WaveGAN without any degradation in sound quality, which verifies the effectiveness of location-variable convolutions.