 A diagram of CACnet
A diagram of CACnetAbstract
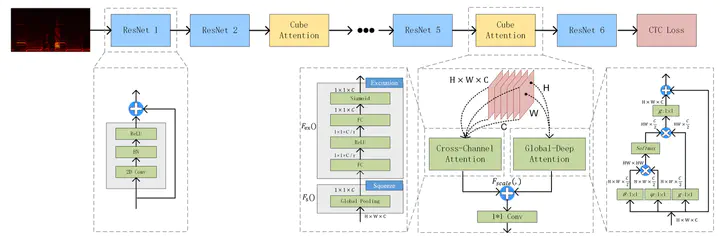
End-to-end models have been widely used in Automatic Speech Recognition (ASR). Convolutional Neural Networks (CNNs) can effectively use spectrum information to model acoustic models. However, the convolution layers have limitations on the receptive field leading to restrictions for long speech signals. Inspired by this, we propose a Cube Attention CNN network(CACnet) that uses two different attention blocks to integrate the feature information of different dimensions for extending context information. Thereinto, the Global Deep Attention Block utilizes non-local operations to compute interactions between any two positions on feature maps and enables the acquirement of global feature representations while the Cross-Channel Attention Block adaptively recalibrates channel-wise feature responses. Then, outputs of the above two attention modules will be added up to further improve the feature representation which contributes to enrich contextual information. Finally, the performance of our proposed architecture will be explored under ASR tasks in English circumstances. Experiments on LibriSpeech indicate that CACnet achieves a word error rate (WER) of 3.78%/9.56% without language model (LM), and 2.84%/6.97% with LM, which is near state-of-the-art accuracy. CACnet on WSJ with 4.4% WER obtains better performance, compared to CTC-based CNN models, such as QuartzNet and Jasper, with the same language model. The proposed network achieves competitive accuracy while having fewer parameters. Moreover, CACnet can be easily incorporated into any existed network since it has the same input and output dimensions.