SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
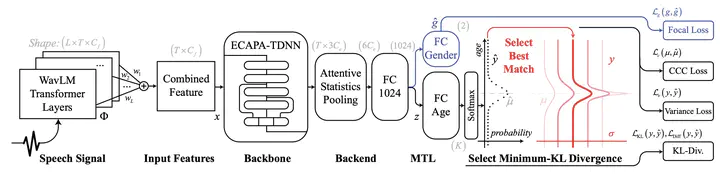 Network topology of the SVLDL framework
Network topology of the SVLDL frameworkAbstract
Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent adjacent indistinguishable ages well, the uncertainty of the age estimate for each utterance varies from person to person, i.e., the variance of the age distribution is different. To address this issue, we propose selective variance label distribution learning (SVLDL) method to adapt the variance of different age distributions. Furthermore, the model uses WavLM as the speech feature extractor and adds the auxiliary task of gender recognition to further improve the performance. Two tricks are applied on the loss function to enhance the robustness of the age estimation and improve the quality of the fitted age distribution. Extensive experiments show that the model achieves state-of-the-art performance on all aspects of the NIST SRE08-10 and a real-world datasets.