 The architecture of the system
The architecture of the systemAbstract
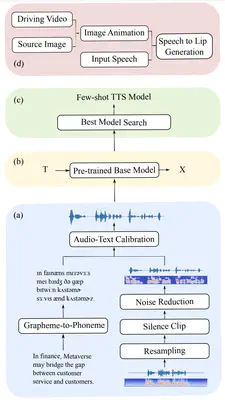
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker’s voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.