 Diagram of the semi-supervised learning method based on backbone network
Diagram of the semi-supervised learning method based on backbone networkAbstract
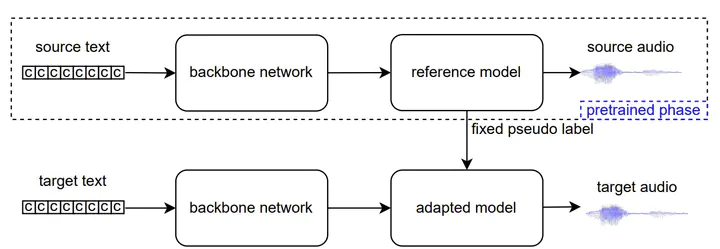
Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large training dataset and hard to achieve comparable performance under low-resource conditions. To ad-dress this issue, we propose a semi-supervised learning method for neural TTS in which labeled target data is limited, which can also resolve the problem of exposure bias in the previous auto-regressive models. Specifically, we pre-train the reference model based on Fastspeech2 with much source data, fine-tuned on a limited target dataset. Meanwhile, pseudo labels generated by the original reference model are used to guide the fine-tuned model’s training further, achieve a regularization effect, and reduce the overfitting of the fine-tuned model during training on the limited target data. Experimental results show that our proposed semi-supervised learning scheme with limited target data significantly improves the voice quality for test data to achieve naturalness and robustness in speech synthesis.