TDASS: Target Domain Adaptation Speech Synthesis Framework for Multi-speaker Low-Resource TTS
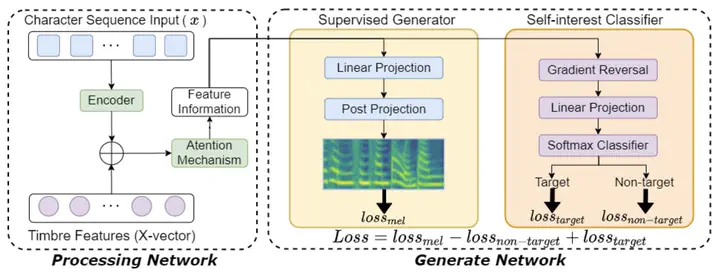 The architecture of the Target Domain Adaptation Speech Synthesis Network (TDASS)
The architecture of the Target Domain Adaptation Speech Synthesis Network (TDASS)Abstract
Recently, synthesizing personalized speech by text-to-speech (TTS) application is highly demanded. But the previous TTS models require a mass of target speaker speeches for training. It is a high-cost task, and hard to record lots of utterances from the target speaker. Data augmentation of the speeches is a solution but leads to the low-quality synthesis speech problem. Some multi-speaker TTS models are proposed to address the issue. But the quantity of utterances of each speaker imbalance leads to the voice similarity problem. We propose the Target Domain Adaptation Speech Synthesis Network (TDASS) to address these issues. Based on the backbone of the Tacotron2 model, which is the high-quality TTS model, TDASS introduces a self-interested classifier for reducing the non-target influence. Besides, a special gradient reversal layer with different operations for target and non-target is added to the classifier. We evaluate the model on a Chinese speech corpus, the experiments show the proposed method outperforms the baseline method in terms of voice quality and voice similarity.