nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-speaker text-to-speech
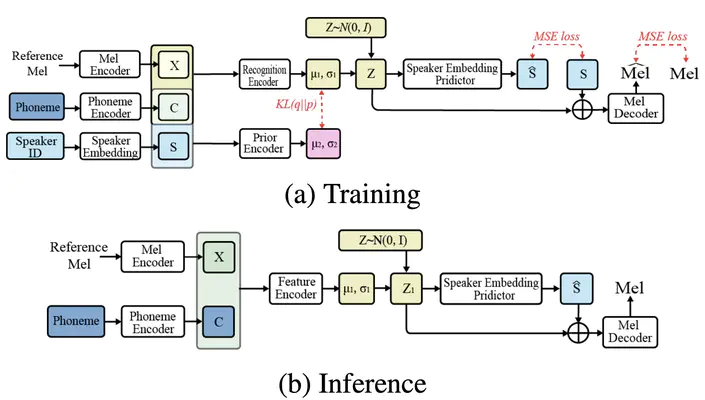 Neural network architectures of nnSpeech
Neural network architectures of nnSpeechAbstract
Multi-speaker text-to-speech (TTS) using a few adaption data is a challenge in practical applications. To address that, we propose a zero-shot multi-speaker TTS, named nnSpeech, that could synthesis a new speaker voice without fine-tuning and using only one adaption utterance. Compared with using a speaker representation module to extract the characteristics of new speakers, our method bases on a speaker-guided conditional variational autoencoder and can generate a variable Z, which contains both speaker characteristics and content information. The latent variable Z distribution is approximated by another variable conditioned on reference mel-spectrogram and phoneme. Experiments on the English corpus, Mandarin corpus, and cross-dataset proves that our model could generate natural and similar speech with only one adaption speech.