 Chinese ASR error correction model based on dynamic error scaling mechanism
Chinese ASR error correction model based on dynamic error scaling mechanismAbstract
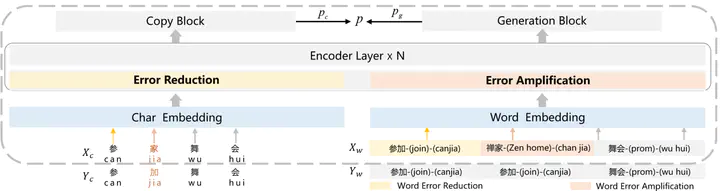
Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language’s unique features, including a large character set and borderless, morpheme-based structure. Current mainstream models often struggle with effectively utilizing word-level features and phonetic information. This paper introduces a novel approach that incorporates a dynamic error scaling mechanism to detect and correct phonetically erroneous text generated by ASR output. This mechanism operates by dynamically fusing word-level features and phonetic information, thereby enriching the model with additional semantic data. Furthermore, our method implements unique error reduction and amplification strategies to address the issues of matching wrong words caused by incorrect characters. Experimental results indicate substantial improvements in ASR error correction, demonstrating the effectiveness of our proposed method and yielding promising results on established datasets.