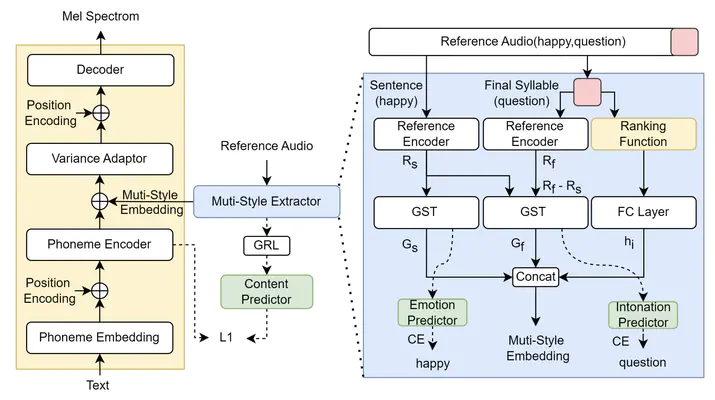
 The overview architecture for QI-TTS
The overview architecture for QI-TTSAbstract
Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation are neglected. In this paper, we propose QI-TTS which aims to better transfer and control intonation to further deliver the speaker’s questioning intention while transferring emotion from reference speech. We propose a multi-style extractor to extract style embedding from two different levels. While the sentence level represents emotion, the final syllable level represents intonation. For fine-grained intonation control, we use relative attributes to represent intonation intensity at the syllable level.Experiments have validated the effectiveness of QI-TTS for improving intonation expressiveness in emotional speech synthesis.