 Conformer Architecture of Dynamic Alignment Mask CTC with Mask and Dynamic Rectification Methods
Conformer Architecture of Dynamic Alignment Mask CTC with Mask and Dynamic Rectification MethodsAbstract
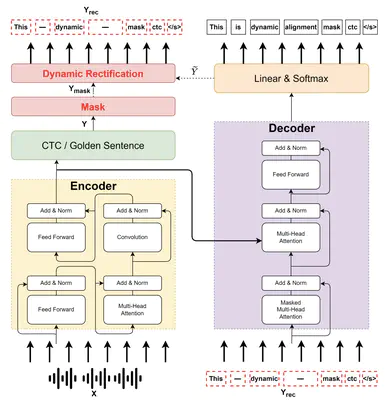
Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of speech recognition compared with traditional autoregressive models. In this work, we present dynamic alignment Mask CTC, introducing two methods{:} (1) Aligned Cross Entropy (AXE), finding the monotonic alignment that minimizes the cross-entropy loss through dynamic programming, (2) Dynamic Rectification, creating new training samples by replacing some masks with model predicted tokens. The AXE ignores the absolute position alignment between prediction and ground truth sentence and focuses on tokens matching in relative order. The dynamic rectification method makes the model capable of simulating the non-mask but possible wrong tokens, even if they have high confidence. Our experiments on WSJ dataset demonstrated that not only AXE loss but also the rectification method could improve the WER performance of Mask CTC.