Learning Expressive Disentangled Speech Representations with Soft Speech Units and Adversarial Style Augmentation
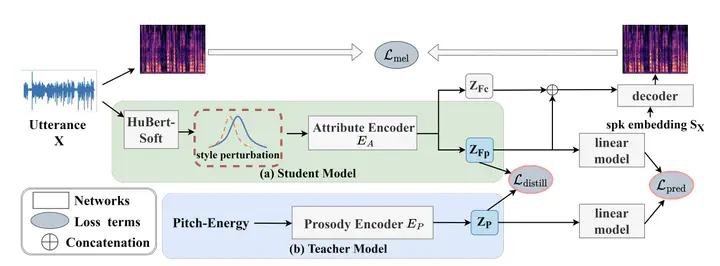 The framework of SAVC
The framework of SAVCAbstract
Voice conversion is the task to transform voice characteristics of source speech while preserving content information. Nowadays, self-supervised representation learning models are increasingly utilized in content extraction. However, in these representations, a lot of hidden speaker information leads to timbre leakage while the prosodic information of hidden units lacks use. To address these issues, we propose a novel framework for expressive voice conversion called “SAVC” based on soft speech units from HuBert-soft. Taking soft speech units as input, we design an attribute encoder to extract content and prosody features respectively. Specifically, we first introduce statistic perturbation imposed by adversarial style augmentation to eliminate speaker information. Then the prosody is implicitly modeled on soft speech units with knowledge distillation. Experiment results show that the intelligibility and naturalness of converted speech outperform previous work.