 The framework of SGLDL
The framework of SGLDLAbstract
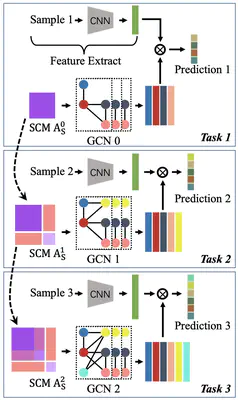
Label Distribution Learning (LDL) is an effective approach for handling label ambiguity, as it can analyze all labels at once and indicate the extent to which each label describes a given sample. Most existing LDL methods consider the number of labels to be static. However, in various LDL-specific contexts (e.g., disease diagnosis), the label count grows over time (such as the discovery of new diseases), a factor that existing methods overlook. Learning samples with new labels directly means learning all labels at once, thus wasting more time on the old labels and even risking overfitting the old labels. At the same time, learning new labels by the LDL model means reconstructing the inter-label relationships. How to make use of constructed relationships is also a crucial challenge. To tackle these challenges, we introduce Incremental Label Distribution Learning (ILDL), analyze its key issues regarding training samples and inter-label relationships, and propose Scalable Graph Label Distribution Learning (SGLDL) as a practical framework for implementing ILDL. Specifically, in SGLDL, we develop a New-label-aware Gradient Compensation Loss to speed up the learning of new labels and represent inter-label relationships as a graph to reduce the time required to reconstruct inter-label relationships. Experimental results on the classical LDL dataset show the clear advantages of unique algorithms and illustrate the importance of a dedicated design for the ILDL problem.