ESARM: 3D Emotional Speech-To-Animation via Reward Model From Automatically-Ranked Demonstrations
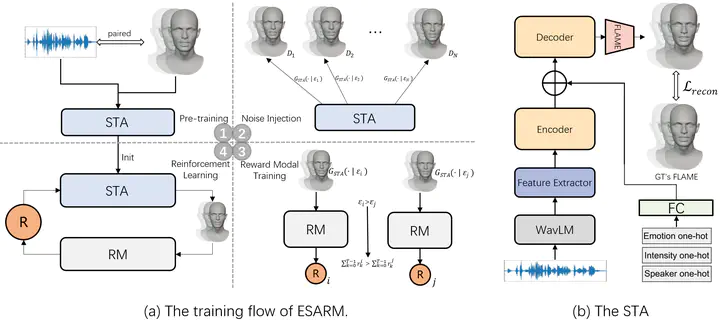 The training flow of ESARM
The training flow of ESARMAbstract
This paper proposes a novel 3D speech-to-animation (STA) generation framework designed to address the shortcomings of existing models in producing diverse and emotionally resonant animations. Current STA models often generate animations that lack emotional depth and variety, failing to align with human expectations. To overcome these limitations, we introduce a novel STA model coupled with a reward model. This combination enables the decoupling of emotion and content under audio conditions through a cross-coupling training approach. Additionally, we develop a training methodology that leverages automatic quality evaluation of generated facial animations to guide the reinforcement learning process. This methodology encourages the STA model to explore a broader range of possibilities, resulting in the generation of diverse and emotionally expressive facial animations of superior quality. We conduct extensive empirical experiments on a benchmark dataset, and the results validate the effectiveness of our proposed framework in generating high-quality, emotionally rich 3D animations that are better aligned with human preferences.