 Our proposed SeCCap
Our proposed SeCCapAbstract
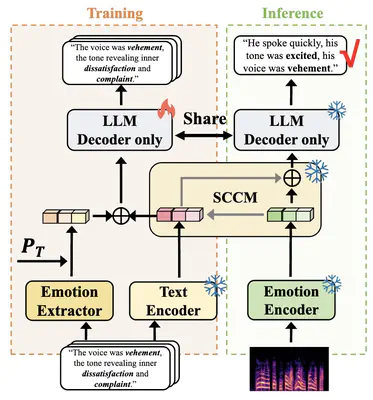
Speech Emotion Captioning (SEC) has emerged as an increasingly prominent research area. The emotional content expressed through human speech is often intricate, making it difficult to fully capture with fixed categorical labels. Instead, describing these emotions using natural language can offer a more comprehensive representation. However, obtaining well-matched speech-caption datasets is challenging in practical scenarios, and existing SEC techniques often generate hallucinated content or miss fine-grained details when working with cross-domain, unpaired data. To address these challenges, we introduce SeCCap, a Semantic-Calibrated Zero-shot Speech Emotion Captioning framework built upon large language models (LLMs). SeCCap exhibits three key features{:} 1) Zero-shot inference{:} It generates speech emotion captions without requiring training on paired speech-caption datasets. 2) Bridging the modality gap {:}It employs caption-only training and semantic-calibrated cross-modal mapping to enhance fine-grained content and reduce factual hallucinations during zero-shot SEC. Experimental results show that SeCCap outperforms other state-of-the-art models in zero-shot SEC tasks.