 Illustration of the knowledge amalgamation and our proposed method
Illustration of the knowledge amalgamation and our proposed methodAbstract
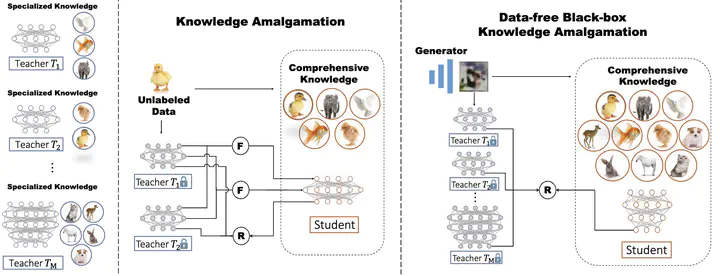
A massive number of well-trained models with promising performances have been released nowadays; exploring reusing them would benefit the community. Some recent works propose to amalgamate multiple models’ pre-learned knowledge and transfer into a single model. They distill knowledge from teachers’ intermediate layers and use unlabeled data as the distilling source. However, in many real-world cases, teachers’ model architectures vary. Thus, aligning the intermediate layers takes a lot of work. Also, the unlabeled data is required to belong to the same domain where teachers pre-learned, which likely is confidential and unavailable. Both constraints would limit the practicability of knowledge amalgamation. To tackle these problems, we propose to treat teacher models as black boxes and only amalgamate teachers’ responses in a data-free manner, thus relaxing both constraints. Further, we validate and address the unfairness and uncertainty issue in the amalgamated response. By entropy transform and subjective re-weighting, we build a confident amalgamated response that can better guide knowledge transfer. Extensive experiments demonstrate that our method can significantly improve performance in various heterogeneous settings.