 The architecture of Rano
The architecture of RanoAbstract
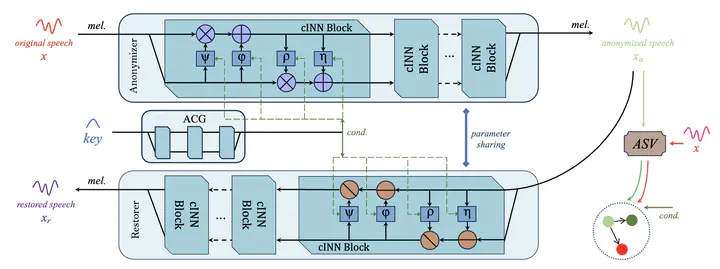
Speech contains ample information, including the primary semantic content and information about the speaker, such as gender, age and health status. Speaker-dependent information partially carries personal privacy and has raised concerns about the protection of voice privacy. Speaker anonymization aims to conceal the speaker’s identity in speech, while preserving speaker-independent information to the greatest extent possible, and has become an increasingly important task in the field of speech. Existing research generally treats speaker anonymization as a downstream task of voice conversion, often employing speech representation disentanglement-based methods to separate speaker-dependent and speaker-independent information. However, speech representation disentanglement, especially for speaker-independent information, faces challenges such as information leakage or excessive disentangling, resulting in quality degradation. In this paper, we propose a speaker anonymization model called Rano, which does not rely on precise disentanglement. Rano employs a generative invertible neural network to forge anonymous speaker identities from keys and then uses the speaker embeddings as conditions to guide the speaker anonymization process via a conditional invertible neural network. Moreover, when the key is provided, lossless restoration from anonymized speech to original speech can be achieved via the reverse network, thereby expanding the application scenarios of Rano. Experiments demonstrate that the proposed model achieves comparable performance to existing state-of-the-art models. We also verify the security guaranteed by the key in the restoration process.