 An illustration of Turbo-TTS
An illustration of Turbo-TTSAbstract
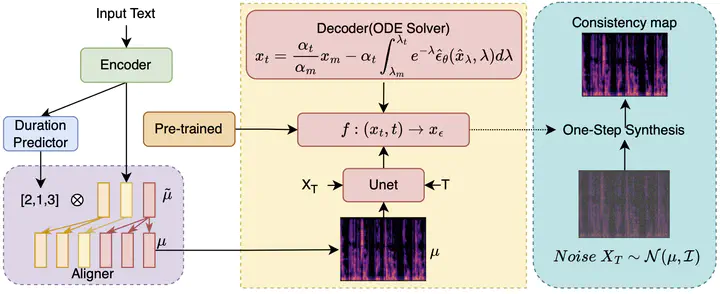
This paper introduces Turbo-TTS, a novel diffusion-based model for text-to-speech (TTS) synthesis. Diffusion models leverage stochastic differential equations (SDEs) to generate high-fidelity speech. To enhance the sampling efficiency of the diffusion process, we propose a new ordinary differential equation (ODE) solver and integrate consistency modeling principles into the TTS framework, leading to significant improvements in synthesized speech quality. Our approach discretizes the underlying SDE describing diffusion into a probability flow ODE (PF ODE). This PF ODE shares the same marginal distribution as the original SDE but offers improved tractability for numerical solution. Experimental evaluations demonstrate that Turbo-TTS produces high-quality speech with substantially reduced computational requirements. The model achieves low-latency synthesis through single-step sampling (NFE = 1, RTF = 0.0074), indicating strong suitability for real-time applications.