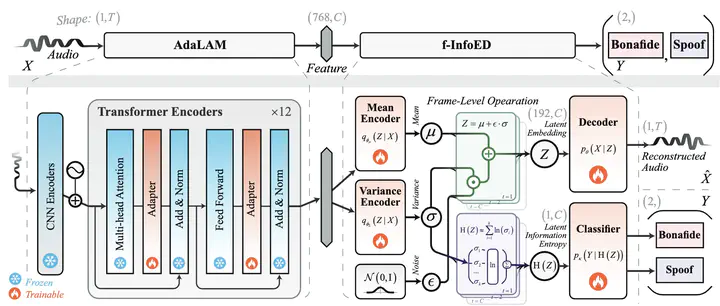
 The overall pipeline of our proposed generalized audio deepfake detection method
The overall pipeline of our proposed generalized audio deepfake detection methodAbstract
Generalizability, the capacity of a robust model to perform effectively on unseen data, is crucial for audio deepfake detection due to the rapid evolution of text-to-speech (TTS) and voice conversion (VC) technologies. A promising approach to differentiate between bonafide and spoof samples lies in identifying intrinsic disparities to enhance model generalizability. From an information-theoretic perspective, we hypothesize the information content is one of the intrinsic differences bonafide sample represents a dense, information-rich sampling of the real world, whereas spoof sample is typically derived from lower-dimensional, less informative representations. To implement this, we introduce frame-level latent information entropy detector(f-InfoED), a framework that extracts distinctive information entropy from latent representations at the frame level to identify audio deepfakes. Furthermore, we present AdaLAM, which extends large pre-trained audio models with trainable adapters for enhanced feature extraction. To facilitate comprehensive evaluation, the audio deepfake forensics 2024 (ADFF 2024) dataset was built by the latest TTS and VC methods. Extensive experiments demonstrate that our proposed approach achieves state-of-the-art performance and exhibits remarkable generalization capabilities. Further analytical studies confirms the efficacy of AdaLAM in extracting discriminative audio features and f-InfoED in leveraging latent entropy information for more generalized deepfake detection.