 Illustration of Shortcut Learning in Vision-Language Models
Illustration of Shortcut Learning in Vision-Language ModelsAbstract
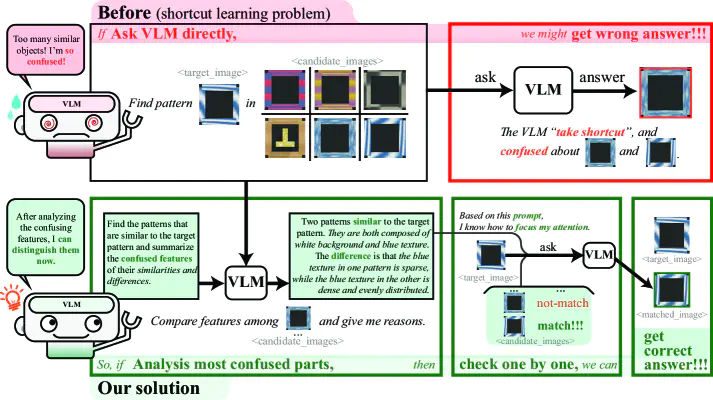
Vision-language models (VLMs) have significantly improved the generalization capabilities of robotic manipulation. However, VLM-based systems often suffer from a lack of robustness, leading to unpredictable errors, particularly in scenarios involving confusable objects. Our preliminary analysis reveals that these failures are mainly caused by shortcut learning problem inherently in VLMs, limiting their ability to accurately distinguish between confusable features. To this end, we propose Confusion-Aware In-Context Learning (CAICL), a method that enhances VLM performance in confusable scenarios for robotic manipulation. The approach begins with confusion localization and analysis, identifying potential sources of confusion. This information is then used as a prompt for the VLM to focus on features most likely to cause misidentification. Extensive experiments on the VIMA-Bench show that CAICL effectively addresses the shortcut learning issue, achieving a 85.5% success rate and showing good stability across tasks with different degrees of generalization.