MirrorTalk: Forging Personalized Avatars via Disentangled Style and Hierarchical Motion Control
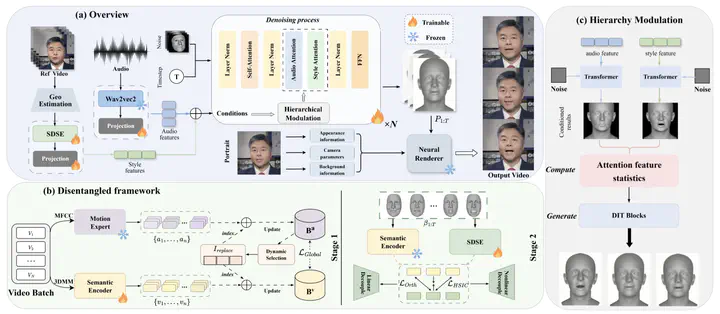 Architecture of MirrorTalk
Architecture of MirrorTalkAbstract
Synthesizing personalized talking faces that uphold and highlight a speaker’s unique style while maintaining lip-sync accuracy remains a significant challenge. A primary limitation of existing approaches is the intrinsic confounding of speaker-specific talking style and semantic content within facial motions, which prevents the faithful transfer of a speaker’s unique persona to arbitrary speech. In this paper, we propose MirrorTalk, a generative framework based on a conditional diffusion model, combined with a Semantically-Disentangled Style Encoder (SDSE) that can distill pure style representations from a brief reference video. To effectively utilize this representation, we further introduce a hierarchical modulation strategy within the diffusion process. This mechanism guides the synthesis by dynamically balancing the contributions of audio and style features across distinct facial regions, ensuring both precise lip-sync accuracy and expressive full-face dynamics. Extensive experiments demonstrate that MirrorTalk achieves significant improvements over state-of-the-art methods in terms of lip-sync accuracy and personalization preservation.