 Overview of CARE
Overview of CAREAbstract
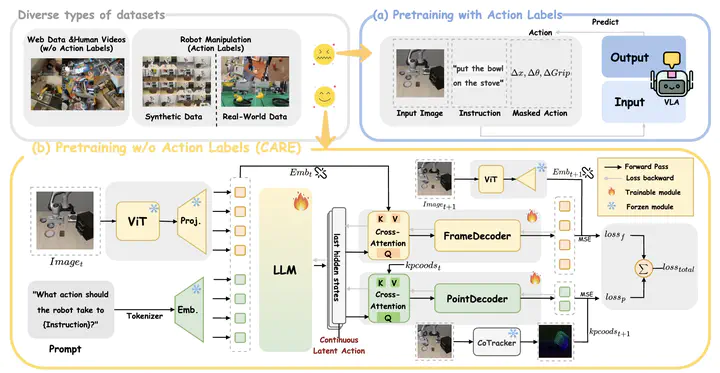
Recent advances in Vision-Language-Action (VLA) models have shown promise for robot control, but their dependence on action supervision limits scalability and generalization. To address this challenge, we introduce CARE, a novel framework designed to train VLA models for robotic task execution. Unlike existing methods that depend on action annotations during pretraining, CARE eliminates the need for explicit action labels by leveraging only video-text pairs. These weakly aligned data sources enable the model to learn continuous latent action representations through a newly designed multi-task pretraining objective. During fine-tuning, a small set of labeled data is used to train the action head for control. Experimental results across various simulation tasks demonstrate CARE’s superior success rate, semantic interpretability, and ability to avoid shortcut learning. These results underscore CARE’s scalability, interpretability, and effectiveness in robotic control with weak supervision.