Triage: Hierarchical Visual Budgeting for Efficient Video Reasoning in Vision-Language Models
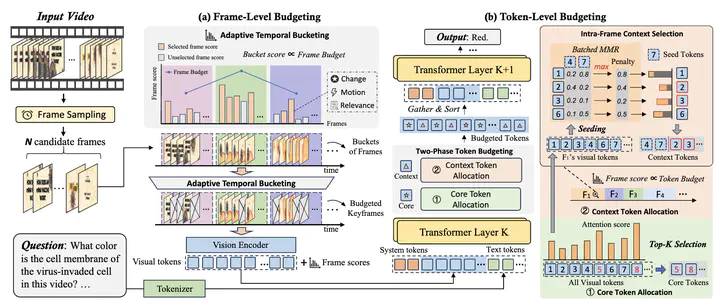 An overview of the Triage framework
An overview of the Triage frameworkAbstract
Vision-Language Models (VLMs) face significant computational challenges in video processing due to massive data redundancy, which creates prohibitively long token sequences. To address this, we introduce Triage, a training-free, plug-and-play framework that reframes video reasoning as a resource allocation problem via hierarchical visual budgeting. Its first stage, Frame-Level Budgeting, identifies keyframes by evaluating their visual dynamics and relevance, generating a strategic prior based on their importance scores. Guided by this prior, the second stage, Token-Level Budgeting, allocates tokens in two phases, it first secures high-relevance Core Tokens, followed by diverse Context Tokens selected with an efficient batched Maximal Marginal Relevance (MMR) algorithm. Extensive experiments demonstrate that Triage improves inference speed and reduces memory footprint, while maintaining or surpassing the performance of baselines and other methods on various video reasoning benchmarks.