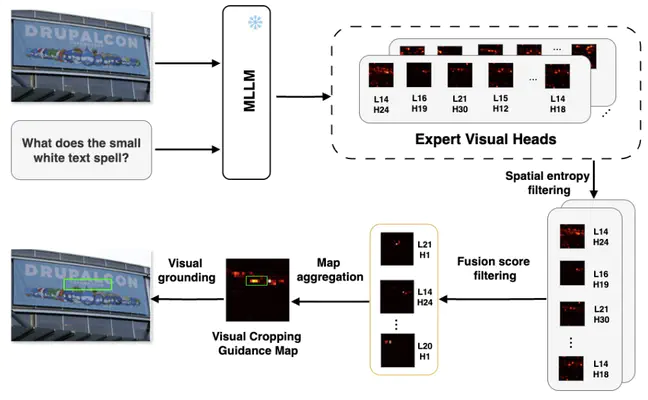
 Overview of the Visual Cropping Guidance Map Generation Process
Overview of the Visual Cropping Guidance Map Generation ProcessAbstract
Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained reasoning due to low-resolution inputs and noisy attention aggregation. We propose \textbf{Head Aware Visual Cropping (HAVC)}, a training-free method that improves visual grounding by leveraging a selectively refined subset of attention heads. HAVC first filters heads through an OCR-based diagnostic task, ensuring that only those with genuine grounding ability are retained. At inference, these heads are further refined using spatial entropy for stronger spatial concentration and gradient sensitivity for predictive contribution. The fused signals produce a reliable Visual Cropping Guidance Map, which highlights the most task-relevant region and guides the cropping of a subimage subsequently provided to the MLLM together with the image-question pair. Extensive experiments on multiple fine-grained VQA benchmarks demonstrate that HAVC consistently outperforms state-of-the-art cropping strategies, achieving more precise localization, stronger visual grounding, providing a simple yet effective strategy for enhancing precision in MLLMs.