Attention-weighted Centered Kernel Alignment for Knowledge Distillation in Large Audio-Language Models Applied to Speech Emotion Recognition
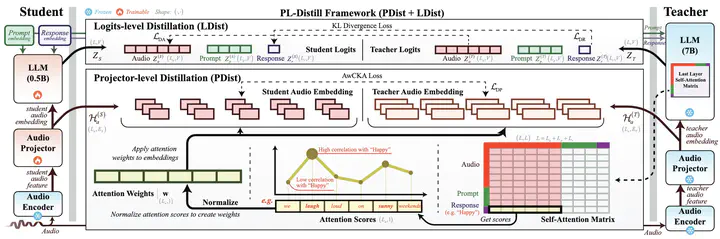 An overview of our PL-Distill framework
An overview of our PL-Distill frameworkAbstract
The emergence of Large Audio-Language Models (LALMs) has advanced Speech Emotion Recognition (SER), but their size limits deployment in resource-constrained environments. While Knowledge Distillation is effective for LALM compression, existing methods remain underexplored in distilling the cross-modal projection module (Projector), and often struggle with alignment due to differences in feature dimensions. We propose PL-Distill, a KD framework that combines Projector-Level Distillation (PDist) to align audio embeddings and Logits-Level Distillation (LDist) to align output logits. PDist introduces Attention-weighted Centered Kernel Alignment, a novel approach we propose to highlight important time steps and address dimension mismatches. Meanwhile, LDist minimizes the Kullback-Leibler divergence between teacher and student logits from audio and text modalities. On IEMOCAP, RAVDESS, and SAVEE, PL-Distill compresses an 8.4B-parameter teacher to a compact 1.1B-parameter student, consistently outperforming the teacher, state-of-the-art pretrained models, and other KD baselines across all metrics.