Home
People
Events
Research
Publications
Contact
News
Audio
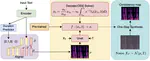
Attention-weighted Centered Kernel Alignment for Knowledge Distillation in Large Audio-Language Models Applied to Speech Emotion Recognition
The emergence of Large Audio-Language Models (LALMs) has advanced Speech Emotion Recognition (SER), but their size limits deployment in …
Qingran Yang
,
Botao Zhao
,
Zuheng Kang
,
Xue Li
,
Yayun He
,
Chuhang Liu
,
Xulong Zhang
,
Xiaoyang Qu
,
Junqing Peng
,
Jianzong Wang
Cite
arXiv
IEEE
MirrorTalk: Forging Personalized Avatars via Disentangled Style and Hierarchical Motion Control
Synthesizing personalized talking faces that uphold and highlight a speaker’s unique style while maintaining lip-sync accuracy …
Renjie Lu
,
Xulong Zhang
,
Xiaoyang Qu
,
Jianzong Wang
,
Shangfei Wang
Cite
arXiv
IEEE
Turbo-TTS: Enhancing Diffusion Model TTS with an Improved ODE Solver
This paper introduces Turbo-TTS, a novel diffusion-based model for text-to-speech (TTS) synthesis. Diffusion models leverage stochastic …
Xulong Zhang
,
Jiashu Wang
,
Xiaoyang Qu
,
Hui Tian
,
Jianzong Wang
Cite
Springer
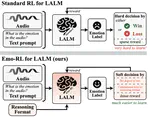
EMO-RL: Emotion-Rule-Based Reinforcement Learning Enhanced Audio-Language Model for Generalized Speech Emotion Recognition
Although Large Audio-Language Models (LALMs) have exhibited outstanding performance in auditory understanding, their performance in …
Pengcheng Li~
,
Botao Zhao
,
Zuheng Kang
,
Junqing Peng
,
Xiaoyang Qu
,
Yayun He
,
Jianzong Wang
Cite
arXiv
ACL
Robust Detection of Partially Spoofed Audio Using Semantic-Aware Inconsistency Learning
Partially spoofed technology subtly manipulates interested parts in an audio to alter the original meaning, with its fine-grained …
Jialu Cao
,
Hui Tian
,
Peng Tian
,
Haizhou Li
,
Jianzong Wang
Cite
IEEE
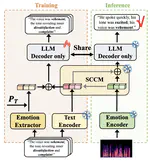
Bridging the Modality Gap: Semantic-Calibrated Zero-shot Speech Emotion Captioning
Speech Emotion Captioning (SEC) has emerged as an increasingly prominent research area. The emotional content expressed through human …
Jianzong Wang
,
Xulong Zhang
,
Xiaoyang Qu
Cite
IEEE
Generalized Audio Deepfake Detection Using Frame-level Latent Information Entropy
Generalizability, the capacity of a robust model to perform effectively on unseen data, is crucial for audio deepfake detection due to …
Botao Zhao
,
Zuheng Kang
,
Yayun He
,
Xiaoyang Qu
,
Junqing Peng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
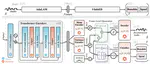
Rano: Restorable Speaker Anonymization via Conditional Invertible Neural Network
Speech contains ample information, including the primary semantic content and information about the speaker, such as gender, age and …
Jianzong Wang
,
Xulong Zhang
,
Xiaoyang Qu
Cite
IEEE
CycleFlow: Leveraging Cycle Consistency in Flow Matching for Speaker Style Adaptation
Voice Conversion (VC) aims to convert the style of a source speaker, such as timbre and pitch, to the style of any target speaker while …
Ziqi Liang
,
Xulong Zhang
,
Chang Liu
,
Xiaoyang Qu
,
Weifeng Zhao
,
Jianzong Wang
Cite
arXiv
IEEE
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional …
Pengcheng Li
,
Xulong Zhang
,
Jing Xiao
,
Jianzong Wang
Cite
Code
arXiv
ACL
DEMO
»
Cite
×