Home
People
Events
Research
Publications
Contact
News
Audio
Communication-Memory-Efficient Decentralized Learning For Audio Representation
Smartphones and wearable devices produce a wealth of audio data, which cannot be accumulated in a centralized repository for learning …
Leilai Li
,
Jianzong Wang
,
Xiaoyang Qu
,
Jing Xiao
Cite
IEEE
Contrastive Learning for improving End-to-end Speaker Verification
Speaker verification involves examining the speech signal to authenticate the claim of a speaker as true or false. Deep neural networks …
Yanxi Tang
,
Jianzong Wang
,
Xiaoyang Qu
,
Jing Xiao
Cite
IEEE
Effective Phase Encoding for End-To-End Speaker Verification
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Junyi Peng
,
Xiaoyang Qu
,
Rongzhi Gu
,
Jianzong Wang
,
Jing Xiao
,
Lukás Burget
,
Jan Cernocký
Cite
ISCA
Best Student Paper Award
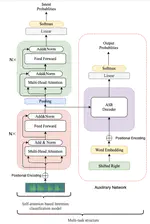
Federated Learning with Dynamic Transformer for Text to Speech
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Zhenhou Hong
,
Jianzong Wang
,
Xiaoyang Qu
,
Jie Liu
,
Chendong Zhao
,
Jing Xiao
PDF
Cite
arXiv
ISCA
ICSpk: Interpretable Complex Speaker Embedding Extractor from Raw Waveform
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Junyi Peng
,
Xiaoyang Qu
,
Jianzong Wang
,
Rongzhi Gu
,
Jing Xiao
,
Lukás Burget
,
Jan Cernocký
PDF
Cite
ISCA
When Hearing the Voice, Who Will Come to Your Mind
Speech is a carrier containing rich biological information, such as speaker identity information including age, gender, race. In this …
Zhenhou Hong
,
Jianzong Wang
,
Wenqi Wei
,
Jie Liu
,
Xiaoyang Qu
,
Bo Chen
,
Zihang Wei
,
Jing Xiao
Cite
IEEE
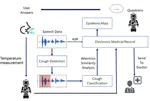
A Real-Time Robot-Based Auxiliary System for Risk Evaluation of COVID-19 Infection
In this paper, we propose a real-time robot-based auxiliary system for risk evaluation of COVID-19 infection. It combines real-time …
Wenqi Wei
,
Jianzong Wang
,
Jiteng Ma
,
Ning Cheng
,
Jing Xiao
PDF
Cite
ISCA
Large-Scale Transfer Learning for Low-Resource Spoken Language Understanding
End-to-end Spoken Language Understanding (SLU) models are made increasingly large and complex to achieve the state-of-the-art accuracy. …
Xueli Jia
,
Jianzong Wang
,
Zhiyong Zhang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
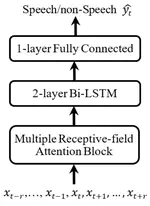
MLNET: An Adaptive Multiple Receptive-Field Attention Neural Network for Voice Activity Detection
Voice activity detection (VAD) makes a distinction between speech and non-speech and its performance is of crucial importance for …
Zhenpeng Zheng
,
Jianzong Wang
,
Ning Cheng
,
Jian Luo
,
Jing Xiao
PDF
Cite
arXiv
ISCA
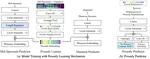
Prosody Learning Mechanism for Speech Synthesis System Without Text Length Limit
Recent neural speech synthesis systems have gradually focused on the control of prosody to improve the quality of synthesized speech, …
Zhen Zeng
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
«
»
Cite
×