Home
People
Events
Research
Publications
Contact
News
Audio
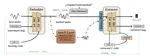
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional …
Pengcheng Li
,
Xulong Zhang
,
Jing Xiao
,
Jianzong Wang
Cite
Code
arXiv
ACL
DEMO
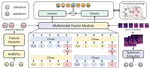
Enhancing Emotion Prediction and Recognition in Conversation through Fine-Grained Emotional Cue Analysis and Cross-Modal Fusion
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual …
Haoxiang Shi
,
Xulong Zhang
,
Ning Cheng
,
Yong Zhang
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Springer
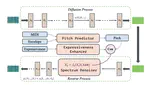
RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing …
Haoxiang Shi
,
Jianzong Wang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
Cite
arXiv
Springer
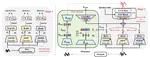
Retrieval-Augmented Audio Deepfake Detection
With recent advances in speech synthesis including text-to-speech (TTS) and voice conversion (VC) systems enabling the generation of …
Zuheng Kang
,
Yayun He
,
Botao Zhao
,
Xiaoyang Qu
,
Junqing Peng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
ACM
CONTUNER: Singing Voice Beautifying with Pitch and Expressiveness Condition
Singing voice beautifying is a novel task that has application value in people’s daily life, aiming to correct the pitch of the …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
DEMO
IEEE
EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot …
Ziqi Liang
,
Jianzong Wang
,
Xulong Zhang
,
Yong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
DEMO
IEEE
EfficientASR: Speech Recognition Network Compression via Attention Redundancy and Chunk-Level FFN Optimization
In recent years, Transformer networks have shown remarkable performance in speech recognition tasks. However, their deployment poses …
Jianzong Wang
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Enhancing Anomalous Sound Detection with Multi-Level Memory Bank
Abnormal sound detection (ASD) is crucial for the timely detection of machine faults in industrial scenarios and has emerged as a …
Baoping Deng
,
Jinggang Chen
,
Zhenhou Hong
,
Xiaoyang Qu
,
Guokuan Li
,
Jiguang Wan
,
Changsheng Xie
,
Jianzong Wang
Cite
IEEE
Learning Expressive Disentangled Speech Representations with Soft Speech Units and Adversarial Style Augmentation
Voice conversion is the task to transform voice characteristics of source speech while preserving content information. Nowadays, …
Yimin Deng
,
Jianzong Wang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
MAIN-VC: Lightweight Speech Representation Disentanglement for One-Shot Voice Conversion
One-shot voice conversion aims to change the timbre of any source speech to match that of the unseen target speaker with only one …
Pengcheng Li
,
Jianzong Wang
,
Xulong Zhang
,
Yong Zhang
,
Jing Xiao
,
Ning Cheng
Cite
arXiv
DEMO
IEEE
«
»
Cite
×