Home
People
Events
Research
Publications
Contact
News
Audio
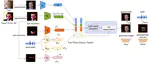
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating …
Bingyuan Zhang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Dataset
IEEE
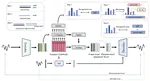
ED-TTS: Multi-Scale Emotion Modeling Using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting …
Haobin Tang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations …
Yimin Deng
,
Huaizhen Tang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Voice conversion as the style transfer task applied to speech, refers to converting one person’s speech into a new speech that …
Yimin Deng
,
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
DEMO
ACM
CLN-VC: Text-Free Voice Conversion Based on Fine-Grained Style Control and Contrastive Learning with Negative Samples Augmentation
Better disentanglement of speech representation is essential to improve the quality of voice conversion. Recently contrastive learning …
Yimin Deng
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
This paper proposes a talking face generation method named “CP-EB” that takes an audio signal as input and a person image as reference, …
Jianzong Wang
,
Yimin Deng
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
DQR-TTS: Semi-supervised Text-to-speech Synthesis with Dynamic Quantized Representation
Most existing neural-based text-to-speech methods rely on extensive datasets and face challenges under low-resource condition. In this …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
VoiceExtender: Short-utterance Text-independent Speaker Verification with Guided Diffusion Model
Speaker Verification (SV) performance gets worse as utterances get shorter. To this end, we propose a new architecture called …
Yayun He
,
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
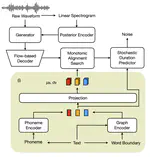
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic …
Jianzong Wang
,
Xulong Zhang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
DEMO
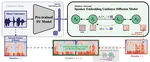
DiffTalker: Co-driven audio-image diffusion for talking faces via intermediate landmarks
Generating realistic talking faces is a complex and widely discussed task with numerous applications. In this paper, we present …
Zipeng Qi
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
Code
arXiv
«
»
Cite
×