Home
People
Events
Research
Publications
Contact
News
Audio
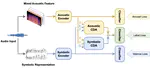
Symbolic and Acoustic: Multi-domain Music Emotion Modeling for Instrumental Music
Music Emotion Recognition involves the automatic identification of emotional elements within music tracks, and it has garnered …
Kexin Zhu
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
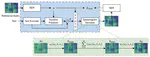
Voice Conversion with Denoising Diffusion Probabilistic GAN Models
Voice conversion is a method that allows for the transformation of speaking style while maintaining the integrity of linguistic …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
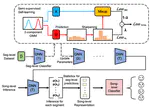
Boosting Chinese ASR Error Correction with Dynamic Error Scaling Mechanism
Chinese Automatic Speech Recognition (ASR) error correction presents significant challenges due to the Chinese language’s unique …
Jiaxin Fan
,
Yong Zhang
,
Hanzhang Li
,
Jianzong Wang
,
Zhitao Li
,
Sheng Ouyang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
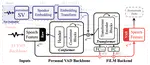
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
DEMO
Investigation of Music Emotion Recognition Based on Segmented Semi-Supervised Learning
The production and annotation of music datasets requires very specialized background knowledge, which is difficult for most people to …
Yifu Sun
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Kaiyu Hu
,
Jing Xiao
PDF
Cite
ISCA
SVVAD: Personal Voice Activity Detection for Speaker Verification
Voice activity detection (VAD) improves the performance of speaker verification (SV) by preserving speech segments and attenuating the …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
PDF
Cite
Slides
arXiv
ISCA
SAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features …
Jianzong Wang
,
Xulong Zhang
,
Haobin Tang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of …
Xulong Zhang
,
Haobin Tang
,
Jianzong Wang
,
Ning Cheng
,
Jian Luo
,
Jing Xiao
Cite
arXiv
IEEE
Improving Music Genre Classification from Multi-modal Properties of Music and Genre Correlations Perspective
Music genre classification has been widely studied in past few years for its various applications in music information retrieval. …
Ganghui Ru
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
Poster
arXiv
IEEE
Learning Speech Representations with Flexible Hidden Feature Dimensions
Non-parallel many-to-many voice conversion is a kind of style transfer task in speech. Recently, AutoVC has been applied in this field …
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
IEEE
«
»
Cite
×