Home
People
Events
Research
Publications
Contact
News
Audio
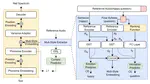
QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
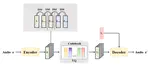
VQ-CL: Learning Disentangled Speech Representations with Contrastive Learning and Vector Quantization
Voice Conversion(VC) refers to converting the voice char- acteristics of audio to another one as it is said by other people. Recently, …
Huaizhen Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
IEEE
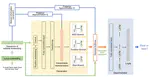
Feature-Rich Audio Model Inversion for Data-Free Knowledge Distillation Towards General Sound Classification
Data-Free Knowledge Distillation (DFKD) has recently attracted growing attention in the academic community, especially with major …
Zuheng Kang
,
Yayun He
,
Jianzong Wang
,
Junqing Peng
,
Xiaoyang Qu
,
Jing Xiao
Cite
arXiv
IEEE
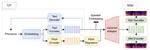
Melody Generation from Lyrics with Local Interpretability
Melody generation aims to learn the distribution of real melodies to generate new melodies conditioned on lyrics, which has been a very …
Wei Duan
,
Yi Yu
,
Xulong Zhang
,
Suhua Tang
,
Wei Li
,
Keizo Oyama
Cite
ACM
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
Adapitch: Adaption Multi-Speaker Text-to-Speech Conditioned on Pitch Disentangling with Untranscribed Data
In this paper, we proposed Adapitch, a multi-speaker TTS method that makes adaptation of the supervised module with untranscribed data. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
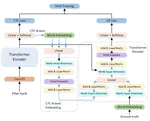
Improving Speech Representation Learning via Speech-level and Phoneme-level Masking Approach
Recovering the masked speech frames is widely applied in speech representation learning. However, most of these models use random …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Kexin Zhu
,
Jing Xiao
Cite
arXiv
IEEE
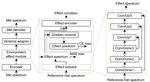
Linguistic-Enhanced Transformer with CTC Embedding for Speech Recognition
The recent emergence of joint CTC-Attention model shows significant improvement in automatic speech recognition (ASR). The improvement …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Mengyuan Zhao
,
Zhiyong Zhang
,
Jing Xiao
Cite
arXiv
IEEE
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
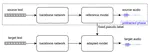
Semi-Supervised Learning Based on Reference Model for Low-resource TTS
Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
«
»
Cite
×