Home
People
Events
Research
Publications
Contact
News
Audio
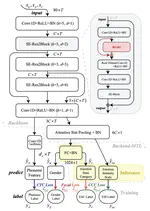
Shallow Diffusion Motion Model for Talking Face Generation from Speech
Talking face generation is synthesizing a lip synchronized talking face video by inputting an arbitrary face image and audio clips. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Edward Xiao
,
Jing Xiao
PDF
Cite
Springer
Boosting Star-GANs for Voice Conversion with Contrastive Discriminator
Nonparallel multi-domain voice conversion methods such as the StarGAN-VCs have been widely applied in many scenarios. However, the …
Shijing Si
,
Jianzong Wang
,
Xulong Zhang
,
Xiaoyang Qu
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
Springer
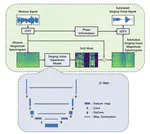
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous …
Aolan Sun
,
Xulong Zhang
,
Tiandong Ling
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
One-shot voice conversion (VC) with only a single target-speaker speech for reference has become a new research direction. Existing …
SiCheng Yang
,
Methawee Tantrawenith
,
Haolin Zhuang
,
Zhiyong Wu
,
Aolan Sun
,
Jianzong Wang
,
Ning Cheng
,
Huaizhen Tang
,
Xintao Zhao
,
Jie Wang
,
Helen Meng
PDF
Cite
arXiv
ISCA
DEMO
SpeechEQ: Speech Emotion Recognition based on Multi-scale Unified Datasets and Multitask Learning
Speech emotion recognition (SER) has many challenges, but one of the main challenges is that each framework does not have a unified …
Zuheng Kang
,
Junqing Peng
,
Jianzong Wang
,
Jing Xiao
PDF
Cite
arXiv
ISCA
Tiny-Sepformer: A Tiny Time-Domain Transformer Network For Speech Separation
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a …
Jian Luo
,
Jianzong Wang
,
Ning Cheng
,
Edward Xiao
,
Xulong Zhang
,
Jing Xiao
PDF
Cite
arXiv
ISCA
Uncertainty Calibration for Deep Audio Classifiers
Although deep Neural Networks (DNNs) have achieved tremendous success in audio classification tasks, their uncertainty calibration are …
Tong Ye
,
Shijing Si
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
ISCA
Investigation of Singing Voice Separation for Singing Voice Detection in Polyphonic Music
Singing voice detection (SVD), to recognize vocal parts in the song, is an essential task in music information retrieval (MIR). The …
Yifu Sun
,
Xulong Zhang
,
Xi Chen
,
Yi Yu
,
Wei Li
Cite
arXiv
Springer
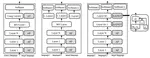
Adaptive Activation Network for Low Resource Multilingual Speech Recognition
Low resource automatic speech recognition (ASR) is a useful but thorny task, since deep learning ASR models usually need huge amounts …
Jian Luo
,
Jianzong Wang
,
Ning Cheng
,
Zhenpeng Zheng
,
Jing Xiao
Cite
arXiv
IEEE
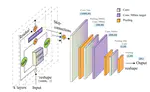
MDCNN-SID: Multi-scale Dilated Convolution Network for Singer Identification
Most singer identification methods are processed in the frequency domain, which potentially leads to information loss during the …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
«
»
Cite
×