Home
People
Events
Research
Publications
Contact
News
Speech
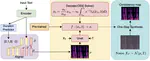
Turbo-TTS: Enhancing Diffusion Model TTS with an Improved ODE Solver
This paper introduces Turbo-TTS, a novel diffusion-based model for text-to-speech (TTS) synthesis. Diffusion models leverage stochastic …
Xulong Zhang
,
Jiashu Wang
,
Xiaoyang Qu
,
Hui Tian
,
Jianzong Wang
Cite
Springer
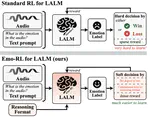
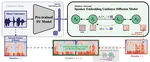
EMO-RL: Emotion-Rule-Based Reinforcement Learning Enhanced Audio-Language Model for Generalized Speech Emotion Recognition
Although Large Audio-Language Models (LALMs) have exhibited outstanding performance in auditory understanding, their performance in …
Pengcheng Li~
,
Botao Zhao
,
Zuheng Kang
,
Junqing Peng
,
Xiaoyang Qu
,
Yayun He
,
Jianzong Wang
Cite
arXiv
ACL
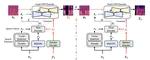
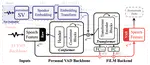
CycleFlow: Leveraging Cycle Consistency in Flow Matching for Speaker Style Adaptation
Voice Conversion (VC) aims to convert the style of a source speaker, such as timbre and pitch, to the style of any target speaker while …
Ziqi Liang
,
Xulong Zhang
,
Chang Liu
,
Xiaoyang Qu
,
Weifeng Zhao
,
Jianzong Wang
Cite
arXiv
IEEE
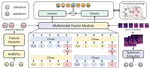
Enhancing Emotion Prediction and Recognition in Conversation through Fine-Grained Emotional Cue Analysis and Cross-Modal Fusion
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual …
Haoxiang Shi
,
Xulong Zhang
,
Ning Cheng
,
Yong Zhang
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Springer
Retrieval-Augmented Audio Deepfake Detection
With recent advances in speech synthesis including text-to-speech (TTS) and voice conversion (VC) systems enabling the generation of …
Zuheng Kang
,
Yayun He
,
Botao Zhao
,
Xiaoyang Qu
,
Junqing Peng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
ACM
Medical Speech Symptoms Classification via Disentangled Representation
Intent is defined for understanding spoken language in existing works. Both textual features and acoustic features involved in medical …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
VoiceExtender: Short-utterance Text-independent Speaker Verification with Guided Diffusion Model
Speaker Verification (SV) performance gets worse as utterances get shorter. To this end, we propose a new architecture called …
Yayun He
,
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
SVVAD: Personal Voice Activity Detection for Speaker Verification
Voice activity detection (VAD) improves the performance of speaker verification (SV) by preserving speech segments and attenuating the …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
PDF
Cite
Slides
arXiv
ISCA
Feature-Rich Audio Model Inversion for Data-Free Knowledge Distillation Towards General Sound Classification
Data-Free Knowledge Distillation (DFKD) has recently attracted growing attention in the academic community, especially with major …
Zuheng Kang
,
Yayun He
,
Jianzong Wang
,
Junqing Peng
,
Xiaoyang Qu
,
Jing Xiao
Cite
arXiv
IEEE
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent …
Zuheng Kang
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
»
Cite
×